Yet another successful Git branching model
A decade ago, Vincent Driessen wrote a post named “A successful Git branching model”. In his post he presents a development model using many Git branches (master, develop, …) well known as the Git flow. Even if I’m not doing professional development for ten years, I got the opportunity to experiment Git flows in many development teams. As explained by his “Note of reflection (March 5, 2020)”, you should not treat this flow as a dogma or panacea. While the flow I will describe in the following lines is inspired by Vincent’s Git flow, it differs in many ways to fit the requirements of development team I’m working with right now at ALLOcloud.
The repository we will talk about has 14,300+ commits, 242.3MB of files and 8 regular contributors (on a daily basis). It contains the code and resources of a heavily used cloud platform including front-end, backend and deployment-as-code developments. It’s some-how a mono-repository. When a developer is working on a new feature, he might have to write code in Javascript or Python but also YAML for Ansible and SQL migration files.
Development vs Deployment
A few months ago, when I joined ALLOcloud team, we were mixing development, release and deployment processes all together. It was, therefore, difficult to know what is in production, what we can/will deploy, what needs to be tested and how tricky will be our next deployment. As a consequence our platform updates were planned on monthly basis with a lot of stress and required a lot of effort (and production patches).
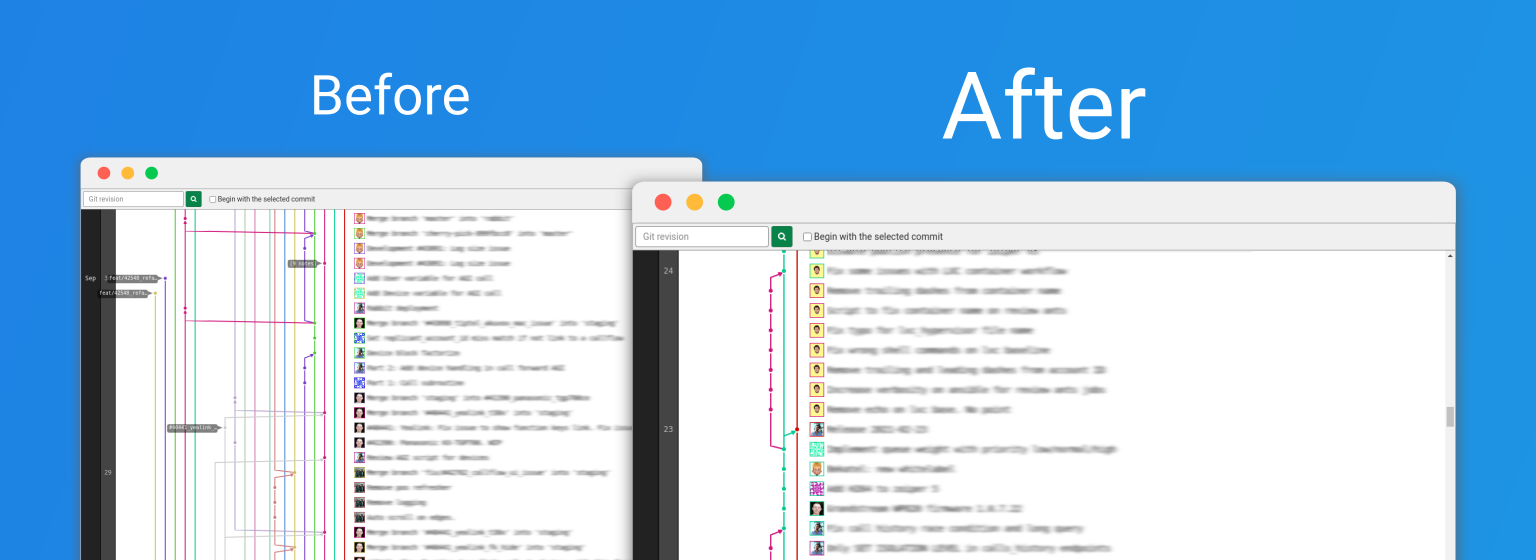
Now we split our development and deployment processes. Thanks to GitLab, we maintain our development cycle in Git and we manage our deployments with GitLab CI and its Environments feature. No more branches for a specific production environment, no more useless merges when we need to deploy, no more duplicated commits or cherry-picks.
Our Git flow
The main branches
The Git repository is organized with two main branches which have more-or-less the same behavior as the Git flow:
- the master branch: each commit in this branch represents a unique production release. It must be a merge commit without fast-forward.
- the develop1 branch: this branch contains atomic feature/bug-fix commits ready to be delivered in production. It means that a commit in develop branch is tested and ready to go in production for our next release.
These two branches already differ from original Git flow because commits in develop branch are already production-ready. It makes the hot-fix branches unnecessary because we can always release from develop branch (bringing sometimes new features while we deploy a hot-fix).
Development of a new feature or a bug fix
Any new development (feature or bug-fix) start with a new working branch from develop. Branches MUST follow the branch name convention. For instance:
git checkout -b features/example develop
It’s now time to write and commit your changes according to the commit conventions. Usually I recommend to use git add -p instead of git add .. That avoids non-related changes and non-atomic commits. Commit as much as you need to achieve your brand new feature. Don’t forget to regulary push your branch.
Now your feature is ready and tested, it’s time to merge in develop branch. Here is how we are merging our changes to avoid conflicts, issues and crappy graph:
-
Rebase your branch on develop. You may have to fix conflicts. Because they are solved during the rebase, you won’t have to do it during the merge. It will also help to keep the Git graph clean and linear.
git fetch --all git rebase --keep-empty --rebase-merges origin developIf you’re working with “Merge request” feature, I recommend you to push to remote repository. Because we rebased our branch, we have to force the push:
git push -f2. -
Now we are ready to execute
git mergecommand. Although we have 2 solutions: a fast-forward or a non-fast-forward merge. We want to keep the whole history of our work (including atomic commits from working branches) so we will prefer non-fast-forward merges (--no-ff). However if your branch contains only one single commit, it’s useless to create a new merge commit. In this case we will only accept fast-forward merge (--ff-only).You can list the number of commits in your branch with:
git cherry -v developSo there are actually 2 ways to merge:
-
If there is only one commit in your branch, merge with fast-forward only:
git checkout develop git merge --ff-only <your_branch> -
If there are multiple commits in your branch, merge with no fast-forward option:
git checkout develop git merge --no-ff --edit <your_branch>Pay attention to the
--edit3 argument. It allows you to edit your merge commit message according to the commit conventions.
-
Merge is done. You can now push and clean-up your branch.
git push
git branch -D <your_branch>
git push --delete origin <your_branch>
Compared to Git flow, we create a commit object only if we have more than 1 commit in the working branch. We also avoid many merge conflicts (usually resolved in merge commit) thanks to the rebase-before-merge.
Releases
When the time has come to do a release, we merge from develop to master with a no-fast-forward merge (--no-ff). Thanks to commit conventions and adaptative merge-fast-forward strategy, I can list the features I will release before merging:
git log --oneline --first-parent master..HEAD # from develop branch
I would also recommend you to tag your releases. Currently we tag the platform releases with a date.
Conclusion
We are now running this flow for a few months. The migration was not an easy task. Changing habits might take a while, but the result is a huge success. Even if the merge strategy is a little bit complex4, we do have a clean repository history with more frequent releases. There are probably some drawbacks that we are not yet aware of. However for now this flow is working fine for our needs.
Conventions
Branches
Working branch names are written with Kebab case and contains 2 parts: <directory>/<name>
- directory: category of the branch (features, bug-fixes, …)
- name: a very short meaning full name
For instance:
features/order-itemsbug-fixes/quote-original-author
Commits
We follow a few rules about our commits:
- A commit MUST be atomic
- A commit MUST NOT contain unrelated changes
- A commit MUST NOT break the build
The commit message MUST follow the rules defined by Chris Beams in his post “How to Write a Git Commit Message”:
- Separate subject from body with a blank line
- Limit the subject line to 50 characters
- Capitalize the subject line
- Do not end the subject line with a period
- Use the imperative mood in the subject line
- Wrap the body at 72 characters
- Use the body to explain what and why vs. how
FAQ
-
Why not always merge with fast-forward ?
We use
git log --first-parenton develop branch to list all features and bug-fixes. With fast-forward merges we would list all the commits of each branch while we only want the summary. -
Do you deploy automatically your changes ?
Release commits in master branch are not deployed automatically. It requires a manual action to deploy on each production environment. Creating a (non-fast-forward merge) commit in this branch only means that we are ready to deploy this state in production.
Commits in develop branch trigger automatic deployment on our staging environment.
-
How can I list changes of a given release ?
Whereas release tag is
releases/2021-03-08, you can execute command:git log --oneline --first-parent releases/2021-03-08~..$(git merge-base releases/2021-03-08 develop)
-
For legacy reason we still call this branch staging. ↩
-
Thanks to GitLab, master and develop are protected,
git push -fis therefore forbidden on these branches. ↩ -
The
--editargument is not required to open your editor. It’s already done with--no-ff. ↩ -
It would be a good idea to write some tooling around Git to automate this merges. ↩